- Home
- Premium Memberships
- Lottery Results
- Forums
- Predictions
- Lottery Post Videos
- News
- Search Drawings
- Search Lottery Post
- Lottery Systems
- Lottery Charts
- Lottery Wheels
- Worldwide Jackpots
- Quick Picks
- On This Day in History
- Blogs
- Online Games
- Premium Features
- Contact Us
- Whitelist Lottery Post
- Rules
- Lottery Book Store
- Lottery Post Gift Shop


The time is now 8:21 pm
You last visited
July 20, 2026, 9:34 pm
All times shown are
Eastern Time (GMT-5:00)

It is all about the SQLPrev TopicNext Topic
-
SQL can be a very important tool to help determine and test strategies.My own preference is to use a combination of SQL and VB. But even if you want to stick to using Excel for analysis, storing the data in a SQL database can add a wide range of options.
SQL Server can be downloaded for free from Microsoft if you don't already have access to it.
SQL can be quite complex, but at it's core the structure is fairly straightforward. Data is queried use a select statement that might look something like this:
Select * from tblHistory
If I wanted to know how many times a number appeared ina particular position I might write something like:
Select Count_Big(*) as Hits, N1 from tblHistory Group by N1 order by Hits Desc
If I wanted to limit it to a specific range of drawing I might do something like:
Select Count_Big(*) as Hits, N1 from tblHistory where drawing between 1 and 50 Group by N1 order by Hits Desc
When I store historical data I assign an integer value to each drawing instead of using dates. There are two reasons why I do this. The first is that integers are much easier to work with than dates. For instance if I want to know the number of drawings since a number last appeared I can just subtract the last appearance drawing from the current drawing.
The second reason is some games don't have drawings every day or have multiple drawings in a single date making date not a very useful detail for analysis.
How SQL statements are constructed can begin to matter one the volume of data being manipulated reaches a certain mass. That mass can vary based on what tasks the server is being asked to perform and the hardware it is installed on.
Yesterday I wrote a program to split the processing of large volumes of historical data between multiple computers. For the last 16 hours it had been humming along at a nice clip without any issues, however about an hour ago I started seeing all kinds of deadlock errors. Deadlocks occur when too many processes are trying to access the same rows of data at the same time.
The thing that had changed in 16 hours was that my feeder table now had several million rows of data in it. Querying it was taking longer per request which resulted in the deadlocks. The original query that I used to lock data was the following:
insert into tblRecordLocks (Drwing , SeqNo , tblName , ProcessID , ComputerName )
Select top 25 Drwing, SeqNo,'tblOddsV2Feeder', 0 , HOST_NAME () from tblOddsV2Feeder as H where
not exists (Select 1 from tblRecordLocks as L where l.Drwing = h.Drwing and l.SeqNo = h.SeqNo )
and not exists (select 1 from tblOddsV2Trends as R where r.Drwing = h.Drwing and r.SeqNo = h.SeqNo )
order by Drwing , SeqNo
By specifying a range drawing range limit on the feeder table I was able to eliminate the deadlocks, saw a reduction in processing time and was able to fire up more instances on each computer.
insert into tblRecordLocks (Drwing , SeqNo , tblName , ProcessID , ComputerName )
Select top 25 Drwing, SeqNo,'tblOddsV2Feeder', 0 , HOST_NAME () from tblOddsV2Feeder as H where h.Drwing between @StartDrwing and @StartDrwing + 2 and
not exists (Select 1 from tblRecordLocks as L where l.Drwing = h.Drwing and l.SeqNo = h.SeqNo )
and not exists (select 1 from tblOddsV2Trends as R where r.Drwing between @StartDrwing and @StartDrwing + 2 and r.Drwing = h.Drwing and r.SeqNo = h.SeqNo )
order by Drwing , SeqNo
Sometimes it is the little things that make all the difference in the world.
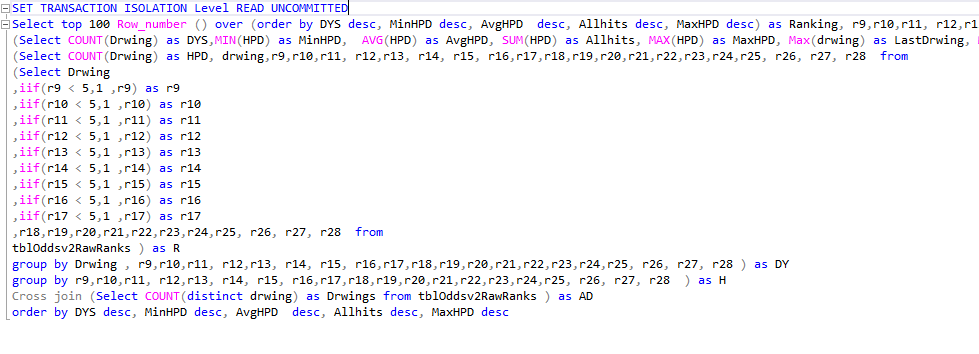
Here is a sample of a reusable query that I use to see patterns in data sets over a series of drawings.
Declare
@SQL varchar(MAx),
@Fields varchar(500),
@TableName varchar(500)
Set @TableName = 'tblOddsv2RawRanks'
Set @Fields = 'r9,r10,r11, r12,r13, r14, r15, r16,r17,r18,r19,r20,r21,r22,r23,r24,r25, r26, r27, r28'
Set @Fields = 'r18,r19,r20,r21,r22,r23,r24,r25, r26, r27, r28'
--Set @Fields = 'CPIDBN2_1,CPIDBN2_2,CPIDBN2_3,CPIDBN2_4, CPIDBN3_1,CPIDBN3_2,CPIDBN3_3,CPIDBN3_4'
--Set @Fields = 'cb4_1,cb4_2,cb4_3,cb4_4,cb4_5,cb4_6,cb4_7,cb4_8,cb4_9,cb4_10 '
Set @SQL =
'SET TRANSACTION ISOLATION Level READ UNCOMMITTED
Select top 100 Row_number () over (order by DYS desc, MinHPD desc, AvgHPD desc, Allhits desc, MaxHPD desc) as Ranking, ' + @Fields +
' , DYS , CAST (dys as decimal(18,12)) / CAST(drwings as decimal(18,12)) as HitPercent, MinHPD , AvgHPD , MaxHPD , Allhits,FirstDrwing, LastDrwing, Drwings as AllDrwings from
(Select COUNT(Drwing) as DYS,MIN(HPD) as MinHPD, AVG(HPD) as AvgHPD, SUM(HPD) as Allhits, MAX(HPD) as MaxHPD, Max(drwing) as LastDrwing, Min(Drwing) as FirstDrwing,' + @Fields + ' from
(Select COUNT(Drwing) as HPD, drwing, ' + @Fields + ' from ' + @TableName + ' group by Drwing , ' + @Fields + ' ) as DY
group by ' + @Fields + ' ) as H
Cross join (Select COUNT(distinct drwing) as Drwings from ' + @TableName + ' ) as AD
order by DYS desc, MinHPD desc, AvgHPD desc, Allhits desc, MaxHPD desc'
print(@SQL)
exec(@SQL)
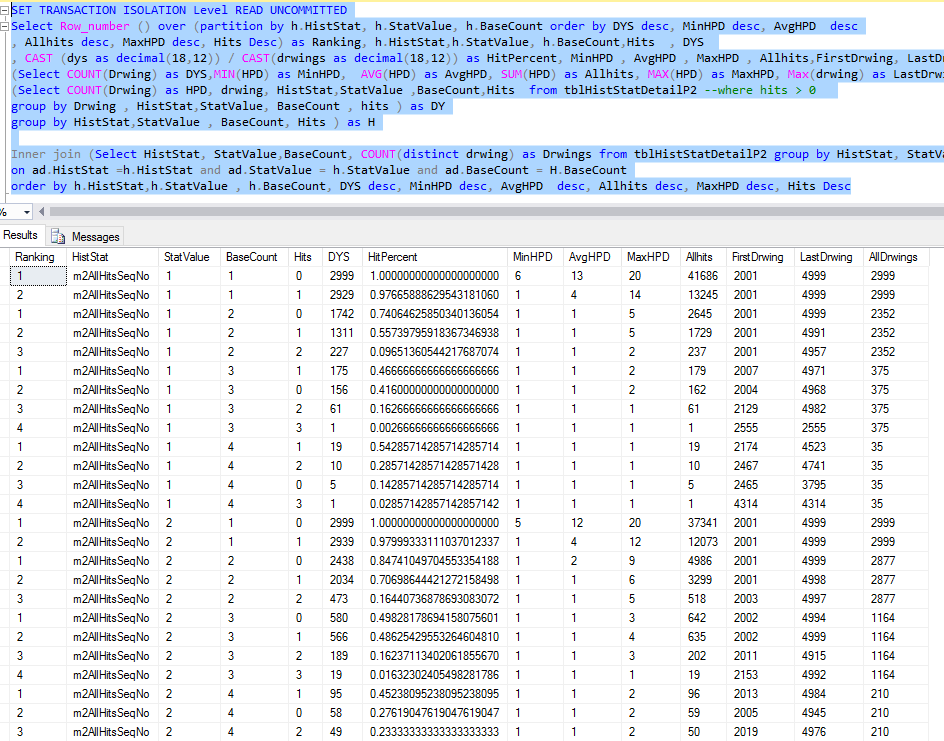
It produces the following results:

The query also produces a written portion that I can modify and run separately:

One example of modifying the query be to do something like the following which would tell me the upper limits of the values that I could choose while still maintaining a pattern. In this example instead of picking values between 1 and 10, I know that I can sustain the pattern with values between 1 and 4:
If you have questions about SQL or need help writing a query please post your questions here and I will do what I can to assist as time allows.
-
-
-
-
-
-
-
-
This format is the primary way that I store my historical drawing data as it makes accessing the winning numbers from a drawing quick and easy.
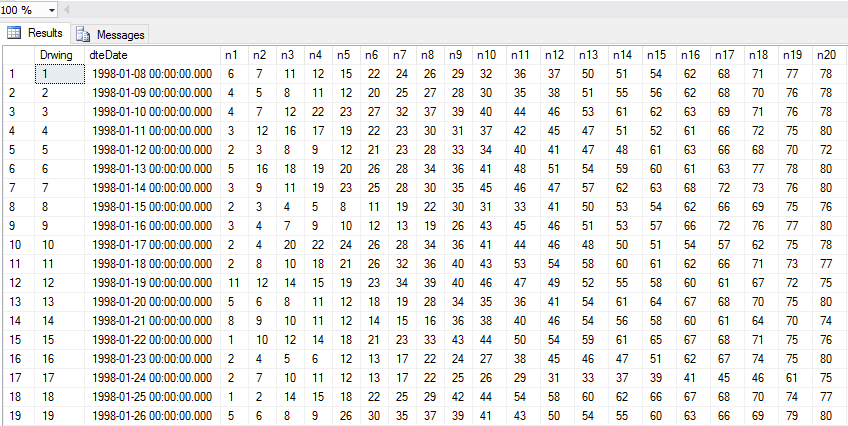
However there are times when I want to crunch some data prior to bringing it into my application so I also store drawing data in the following format. Here are samples from NY Lotto and Pick 10.


With games like Lotto and MM that have additional numbers I use the value of 99 in the position field to separate it from the other numbers.
I'm not someone who likes to do things twice so on the table that has a single row for the drawing I added the following trigger:
CREATE TRIGGER [dbo].[trgInsertWinDigits]
ON [dbo].[tblWinNums]
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
declare
@Clm varchar(20),
@SQL varchar(500),
@Pos varchar(10)
declare Num cursor for
Select COLUMN_NAME from INFORMATION_SCHEMA.COLUMNS where TABLE_NAME = 'tblWinNums' and (COLUMN_NAME like'N%' or COLUMN_NAME like'B%')
open Num
fetch next from num into @clm
while @@FETCH_STATUS = 0
Begin
if @Clm like'N%'
begin
set @pos = replace(@Clm , 'N','')
end
else
begin
set @Pos = '99'
end
Set @SQL = 'insert into tblWindigits (Drwing, pos, N0) Select drwing,' + @pos + ' as Pos, ' + @Clm + ' as N0
from tblWinNums as W where not exists (Select 1 from tblwindigits as D where W.Drwing = d.drwing and d.N0 = ' + @Clm + ' )'
exec(@SQL)
fetch next from num into @clm
end
close num
deallocate num
END
GO
ALTER TABLE [dbo].[tblWinNums] ENABLE TRIGGER [trgInsertWinDigits]
GO
What this trigger does is that after a row is inserted into the Winnums table it will then update the Windigits table with any missing drawing data. This routine works on all of the games that I track and I should not have to modify if I decided to start tracking a new game like PB.
-
One reason to store historical drawing data by digit instead of a single entry is that it opens the door to collect some summary data prior to bringing it into the application or spreadsheet. In the following query I have already chosen 1 and 20 and am interested in seeing how the remaining numbers have performed with those numbers.
Select N0, Max(Drwing) as LastDrwing, Min(DrwingSeq )-1 as SEP, Max(IAR) as IAR, COUNT_BIG (*) as HPP from
(Select n0, Drwing , DrwingSeq , SeqNo , iif(drwingseq= seqno, seqno, 0) as IAR from
(Select N0 , h.Drwing,d.DrwingSeq, ROW_NUMBER () over(partition by n0 order by h.drwing desc) as SeqNo from tblwindigits as H inner join
(Select Drwing, ROW_NUMBER () over(partition by 1 order by drwing desc) as DrwingSeq from tblWinDigits where drwing < 1000 and pos < 99 and n0 in (1,20)
group by Drwing having COUNT_BIG (*) = 2) as D on h.Drwing = d.Drwing
where n0 not in (1,20 ) and pos < 99) as DL ) as S group by N0 order by SEP , iar, HPP
Here are the results it produces for P6 and P10.


I have almost 7000 Pick 10 and a half million Quick Draw drawings in my database and the query runs in less than a second (QD can take 1-3 seconds depending on what drawing I am starting from) whether I'm checking 1 digit or 9. This is much faster than loading the drawings into my application and then processing the history one drawing at a time.
This query will only work on SQL Server 2012 and up.
-
Made some changes.
Added performance in the last 7,14,21,28 and 100 drawings.
Added the "Num" columns which track the individual number history.
I normally run the script from within my code, but made it so that it can be run from a query window without having to edit the query
declare
@Drwing varchar(20) = 1000,
@Nums varchar(500) = '1,5',
@SQL varchar(MAx),
@NumCount varchar(20)
SELECT @NumCount = LEN(@nums) - LEN(REPLACE(@Nums, ',', '')) + 1
Set @SQL = ' Select n.n0, numLastDrwing, numSEP , numIAR , numLifetimeHits, numHPP7, numHPP14 , numHPP21 , numHPP28, numHPP100
, isnull(LastDrwing,0) as LastDrwing , isnull(SEP,9999) as SEP , isnull(IAR,0) as IAR
, isnull(LifetimeMatch,0) as LifetimeMatch , isnull(HPP7,0) as HPP7 , isnull(HPP14,0) as HPP14
,isnull( HPP21,0) as HPP21 , isnull(HPP28,0) as HPP28 , isnull(HPP100,0) as HPP100
from
(Select N0, Max(Drwing) as numLastDrwing, Min(DrwingSeq )-1 as numSEP, Max(IAR) as numIAR, COUNT_BIG (*) as numLifetimeHits
, Sum(iif( DrwingSeq < 8 , 1 , 0)) as numHPP7, Sum(iif( DrwingSeq < 15 , 1 , 0)) as numHPP14
, Sum(iif( DrwingSeq < 22 , 1 , 0)) as numHPP21, Sum(iif( DrwingSeq < 29 , 1 , 0)) as numHPP28
, Sum(iif( DrwingSeq < 101 , 1 , 0)) as numHPP100
from
(Select n0, Drwing , DrwingSeq , SeqNo , iif(drwingseq= seqno, seqno, 0) as IAR from
(Select N0 , h.Drwing,d.DrwingSeq, ROW_NUMBER () over(partition by n0 order by h.drwing desc) as SeqNo from tblwindigits as H inner join
(Select Drwing, ROW_NUMBER () over(partition by 1 order by drwing desc) as DrwingSeq From tblWinNums where drwing < ' + @Drwing +' ) as D on H.Drwing = d.Drwing
where n0 not in (' + @Nums +' ) and pos < 99) as DL) as S group by N0) as N
left outer join
(Select N0, Max(Drwing) as LastDrwing, Min(DrwingSeq )-1 as SEP, Max(IAR) as IAR, COUNT_BIG (*) as LifetimeMatch
, Sum(iif( DrwingSeq < 8 , 1 , 0)) as HPP7, Sum(iif( DrwingSeq < 15 , 1 , 0)) as HPP14
, Sum(iif( DrwingSeq < 22 , 1 , 0)) as HPP21, Sum(iif( DrwingSeq < 29 , 1 , 0)) as HPP28
, Sum(iif( DrwingSeq < 101 , 1 , 0)) as HPP100
from
(Select n0, Drwing , DrwingSeq , SeqNo , iif(drwingseq= seqno, seqno, 0) as IAR from
(Select N0 , h.Drwing,d.DrwingSeq, ROW_NUMBER () over(partition by n0 order by h.drwing desc) as SeqNo from tblwindigits as H inner join
(Select Drwing, ROW_NUMBER () over(partition by 1 order by drwing desc) as DrwingSeq from tblWinDigits where drwing < ' + @Drwing +' and pos < 99 and n0 in (' + @Nums +')
group by Drwing having COUNT_BIG (*) = ' + @NumCount + ') as D on h.Drwing = d.Drwing
where n0 not in (' + @Nums +' ) and pos < 99) as DL ) as S group by N0 ) as M on n.n0 = m.N0 '
exec(@SQL)

-
SQL has something called functions that can be used to handle calculations and operations that are repeated. The following is an example of functions in use. One function determines whether a number is odd or even and then other does what I refer to as basing (although I'm sure there is some proper mathematical term for it).

Here is the code for those functions:
IF OBJECT_ID (N'dbo.UT_FN_OddEven', N'FN') IS NOT NULL
DROP FUNCTION dbo.UT_FN_OddEven;
GO
CREATE FUNCTION dbo.UT_FN_OddEven (@Number decimal(18,3))
RETURNS Bigint
WITH EXECUTE AS CALLER
AS
BEGIN
Declare
@R1 decimal(18,3),
@Result tinyint
Set @R1 = (@Number / cast( 2 as decimal(18,3)) )
Set @Result = 0
if @R1 <> floor(@R1) set @Result = 1
return @result
End
GO
IF OBJECT_ID (N'dbo.UT_FN_BaseN', N'FN') IS NOT NULL
DROP FUNCTION dbo.UT_FN_BaseN;
GO
CREATE FUNCTION dbo.UT_FN_BaseN (@BaseN decimal(18,3) ,@Number decimal(18,3),@ReturnRoot bit)
RETURNS Bigint
WITH EXECUTE AS CALLER
AS
BEGIN
Declare
@R1 decimal(18,3),
@R2 decimal(18,3),
@Result BigInt
Set @R1 = (@Number / @BaseN )
Set @R2 = Floor(@R1)
Set @Result = @R2 * @BaseN
if @R1 > @R2 set @Result = @Result + @BaseN
if @ReturnRoot = 1 set @Result = @Result /@BaseN
return @result
End
-
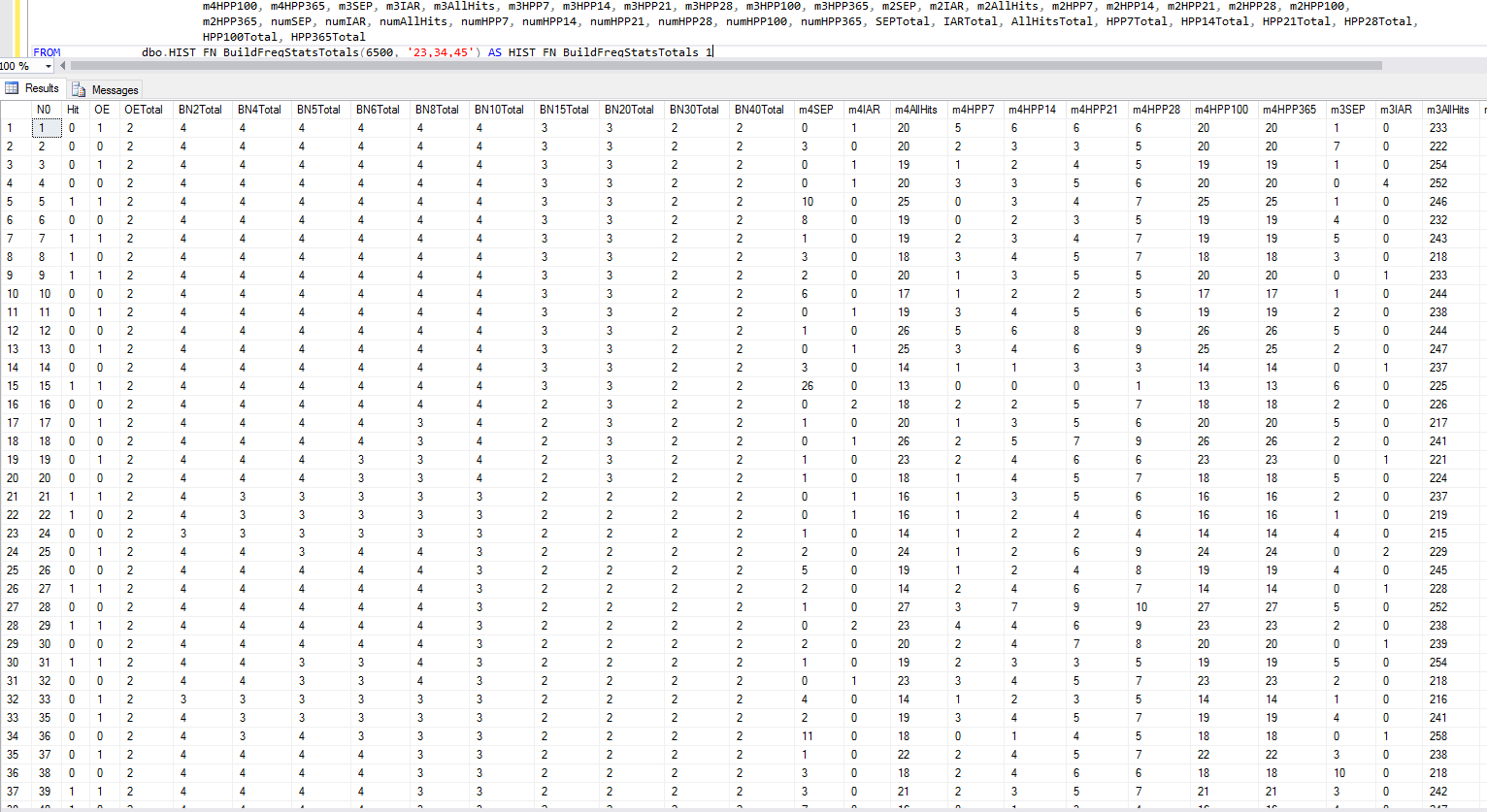
By combining the Odd/Even Functions along with some routines to pull last hit, in a row and hits in X drawings makes it possible to get detailed information on numbers going into the next drawing with a simple query.

Here is the SQL to build this function:
IF OBJECT_ID ('dbo.HIST_FN_N0Stats', N'TF') IS NOT NULL
DROP FUNCTION dbo.HIST_FN_N0Stats;
go
Create Function dbo.HIST_FN_N0Stats(@Drwing int ,@IncludeNums Varchar(500), @ExcludeNums VarChar(500))
returns @tblStats Table
(
N0 TinyInt,
Hit bit,
OE Bit,
BN2 tinyInt,
BN4 tinyInt,
BN5 tinyInt,
BN6 tinyInt,
BN8 tinyInt,
BN10 tinyInt,
BN15 tinyInt,
BN20 tinyInt,
BN30 tinyInt,
BN40 tinyInt,
numSEP int,
numIAR tinyint,
numAllHits int,
numAllHitsSeqNo tinyint,
numHPP7 tinyint,
numHPP14 tinyint,
numHPP21 tinyint,
numHPP28 tinyint,
numHPP100 tinyInt,
numHPP365 int,
Primary key (n0)
)
as begin
declare
@Marker tinyint,
@Value tinyint,
@TempStr varchar(500)
declare @tblExludeNums table(
N0 tinyint
primary key (n0))
declare @tblIncludeNums table(
N0 tinyint
primary key (n0))
set @TempStr =@ExcludeNums + ','
Set @Marker = (Select charindex(',',@TempStr ))
While @Marker <> 0
begin
Select @Value = (select substring(@TempStr ,1, @Marker - 1))
set @TempStr = (select right(@TempStr ,len(@TempStr )-@Marker ))
Set @Marker = (Select charindex(',',@TempStr ))
insert into @tblExludeNums (N0 ) values (@Value)
end
set @TempStr =@IncludeNums + ','
Set @Marker = (Select charindex(',',@TempStr ))
While @Marker <> 0
begin
Select @Value = (select substring(@TempStr ,1, @Marker - 1))
set @TempStr = (select right(@TempStr ,len(@TempStr )-@Marker ))
Set @Marker = (Select charindex(',',@TempStr ))
insert into @tblIncludeNums (N0 ) values (@Value)
end
insert into @tblStats
Select n.n0, ISNULL (w.hit, 0) as Hit
, dbo.UT_FN_OddEven (n.N0) as OE
, dbo.UT_FN_BaseN (2,n.n0,1) as BN2
, dbo.UT_FN_BaseN (4,n.n0,1) as BN4
, dbo.UT_FN_BaseN (5,n.n0,1) as BN5
, dbo.UT_FN_BaseN (6,n.n0,1) as BN6
, dbo.UT_FN_BaseN (8,n.n0,1) as BN8
, dbo.UT_FN_BaseN (10,n.n0,1) as BN10
, dbo.UT_FN_BaseN (15,n.n0,1) as BN15
, dbo.UT_FN_BaseN (20,n.n0,1) as BN20
, dbo.UT_FN_BaseN (30,n.n0,1) as BN30
, dbo.UT_FN_BaseN (40,n.n0,1) as BN40
, numSEP , numIAR , numAllHits , 0 as numAllHitsSeqNo, numHPP7, numHPP14 , numHPP21 , numHPP28, numHPP100, numHPP365
from
(Select N0, Max(Drwing) as numLastDrwing, Min(DrwingSeq ) as numSEP, Max(IAR) as numIAR, COUNT_BIG (*) as numAllHits
, Sum(iif( DrwingSeq < 8 , 1 , 0)) as numHPP7, Sum(iif( DrwingSeq < 15 , 1 , 0)) as numHPP14
, Sum(iif( DrwingSeq < 22 , 1 , 0)) as numHPP21, Sum(iif( DrwingSeq < 29 , 1 , 0)) as numHPP28
, Sum(iif( DrwingSeq < 101 , 1 , 0)) as numHPP100, Sum(iif( DrwingSeq < 366 , 1 , 0)) as numHPP365
from (Select n0, Drwing , DrwingSeq , SeqNo , iif(drwingseq= seqno, seqno, 0) as IAR from
(Select N0 , h.Drwing,d.DrwingSeq, ROW_NUMBER () over(partition by n0 order by h.drwing desc) as SeqNo from tblwindigits as H inner join
(Select Drwing, ROW_NUMBER () over(partition by 1 order by drwing desc) as DrwingSeq From tblWinNums where drwing < @Drwing ) as D on H.Drwing = d.Drwing
where (
(@ExcludeNums = @IncludeNums ) or
(len(@ExcludeNums ) > 0 and n0 not in (select n0 from @tblExludeNums )) or
(len(@IncludeNums ) > 0 and n0 in (select n0 from @tblIncludeNums ))
) and pos < 99) as DL) as S group by N0) as N
left outer join (Select N0, 1 as Hit from tblWinDigits where Drwing = @Drwing ) as W on w.N0 = n.N0
update @tblStats Set numAllHitsSeqNo = AllHitsSeqNo from @tblStats as S inner join
(Select numAllHits , ROW_NUMBER () over (partition by 1 Order by NumAllHits ) as AllHitsSeqNo from
(Select numAllHits , Count(*) as Hits from @tblStats group by numAllHits ) as S) as H on s.numAllHits = h.numAllHits
return
end
-
With some additional work a function could be written to show what the statistics are for the numbers that have already been picked and what combinations the remaining numbers would produce if they were picked.
For analysis purposes I included a flag to indicate whether or not the number hit in the current drawing. In looking at this I this data I can see that the combination that had gone the longest without hitting hits in the current drawing.
-
One of the strengths of a SQL database is that it opens the door to being able to look at large chunks of date in a wide variety of ways. In the sample of data posted below what I did was take the 20 winning numbers from 3,000 drawings, paired them up with each other and looked at what their totals were compared to the other available numbers in a given drawing. It took about 4 hours for two computers to process the data.
The statistic that I chose to look at was lifetime hits. Because lifetime hits changes with each drawing I chose to assign a sequential value to each block of hits based on the lowest to highest frequency.
What this tells me is that when the 20 winners are paired with the other 60 numbers and the total count of numbers that have appeared the least with that number is one, that 90% of the time it will appear in the next drawing. It also tells me that on average 13 of the 20 will not hit. It also shows that when there are 2 or more that there is only a 10 percent chance that both will appear so ideally I would want to avoid combinations involving two of those numbers which could be validated in real time as I was picking the numbers.